17 June 2010
Emotions constrained - voicing the sounds of sighs
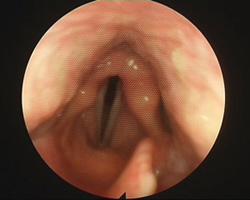
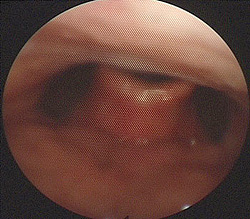
 Image: Blind listening
Image: Blind listening At a time when political systems collapse around us - weighed down by complexities entangled in constraint - ideas that once offered the way forward to liberating circumstances now draw us to question why it is that voices frequently evoke tempered emotions. Codes of behaviour often expect us to sanitise vocal expression - particularly when issues involving passionate belief are involved. Where is the voice now? And what has been made of singing from the heart?
'Whoa-oa-oa!' - the opening scream from the song 'I Feel Good' by James Brown is an example of a heartfelt voice expressing joy. 'Whoa-oa-oa!' is also an example of vocal constriction (pharyngeal constriction). This occurs when the vocal folds (or vocal chords) - the fleshy structures in the larynx that produce the sound of the voice - have been compromised. Instead of vibrating freely, the folds slam together in a compressed space producing a distorted sounding voice. This can be described in a variety of ways such as 'glottal fry' or 'dis' - short for distortion.
If the voice is consistently constrained in this manner - through continual shouting for example - damage can occur where a callous or nodules form. Vocal folds with nodules are denied full closure; they no longer operate effectively because the nodules inhibit free sympathetic bilateral vibration. As a result, the voice produces a hoarse or 'raspy' sound, or sometimes no sound at all.
There is a healthy way of shouting however, using diaphragmatic breathing and body stabilisation - where the breath vibrates the vocal folds without constraining them or the larynx. This is how James Brown achieves 'Whoa-oa-oa!'. The sound can also be produced by using the false folds which is how the 'death growl' is made by many heavy metal singers.
Emotive utterances expressing a diverse range of feelings - such as contentment, frustration, anger, joy, triumph, sadness - might all be made using pharyngeal constriction. There is a fine line between the auditory perception of pleasure and pain - or even in identifying the mixed emotion of painful pleasure - our primal ears being instinctively tuned to the distinction between such emotive vocal qualities.
When we hear a voice sing a song, we are listening to a stylised vocal emotive expression - a kind of concentrated, contrived sonic sculpture in time. Take the sound of a voiced sad sigh, for example: the sound might last for a few seconds. Stretch the sonic quality of that voiced sigh, enunciated through a text to last a couple of minutes - that is the essence of a sad song. Sad songs are usually sung using a voice quality described as 'cry': 'You're Beautiful' by James Blunt, for example, or 'Delilah' (Reed/Mason), sung by Tom Jones: from a gentle sobbing to a restrained howling, a moan, and a selection of falling pitches or cries....
A great example of 'cry' quality can be heard in most of the songs sung by Billy Holliday - the blues 'cry' quality. Within 'cry' quality there are an infinite number of nuances.
Similarly there are different terms for describing the variety of categorised voice qualities (as researtched by Jo Estill): speech - twang - belt - howl belt - shout belt - sob - breathy - falsetto - nasal - creak - opera - choral - croon and cry, to name a few. The sounds associated with these voice qualities have evolved over the period of human history as responses to human emotions such as fear, anger, disgust, sadness, surprise, and joy. The sounds the voice makes in response to these feelings acts as a communicative signifier to indicate the expression of a particular emotion or mixture of emotions. The relationships formed between the vocal sound and the space in which the sound was usually heard became connected and intuitively understood. Voice qualities became associated with or framed in particular spatial contexts:
- smaller intimate spaces: speech - breathy
- large outdoor spaces: belt or shout qualities
- reverberant places of worship: sob - breathy - falsetto
All this changed with the development of audio recording, radio transmission and the use of the microphone and amplification. In the early to mid-twentieth century, these technologies favoured the intimate qualities of speech, cry, sob and breathy, and not the qualities of shout, belt or opera - although opera was initially the most favoured recorded medium. Belt and opera qualities were more compatible with large live reverberant spaces.
These sounds reproduced poorly when recorded because of the wide dynamic range of the medium and the narrow dynamic range of early shellac recordings. These early recordings were better at representing the narrow bandwidth of sounds around a mid-range register - the register being most sympathetic to the baritone voice. Higher voices tended to sound thin, squeaky or scratchy, and not as convincingly reproduced.
One of the results of this was that radio began to favour the sound of the smooth baritone voice of the 'crooner'. Bing Crosby's voice became a template for defining the intimate radio listening experience - the listener drawn into the illusion that the broadcast voice was singing or speaking to them individually. This had a great influence on the formation of the popular song - a song produced and arranged as a recording, heard and transmitted as a recording and written and arranged to account for the sonic limitation of the recording process and radio airplay.
The most popular female radio stars tended to be those singing with the intimate sound of speech, twang or croon quality: Mahalia Jackson, Ella Fitzgerald, Marlene Dietrich, Gracie Fields, Judy Garland, Lena Horn, the Andrews Sisters, Kate Smith, Doris Day, Ethel Merman, Yma Sumac (there were exceptions: Merman and Sumac used belt and opera quality, respectively, but recorded using spatial recording techniques where one microphone captures all and the balance between voice and musicians is determined by the performers).
An important thing happened as a result of the introduction and developments in broadcast and associated technologies. Our experience as listeners began to alter: associations that coupled space type with the quality of the sound of a voice underwent reconfiguration. This had an impact on our intuitive emotive vocal quality identifier abilities - that bank of sonic knowledge that makes it possible for our ear to identify the sound of danger, for example.
Broadcasting reshaped ideas about the acousmatic voice (term first used by Pierre Schaeffer): the voice one hears without seeing the speaker of the voice. Radio exploited the use of vocal qualities by manipulating and subverting ideas about character and the disembodied voice in multiple ways, both expected and unexpected.
Throughout the twentieth century, changes in technologies and the 'volume of the world' continued to affect the way we hear and how we register what it is that we hear. Sounds became increasingly diverse in nature, their tonal structures widening over extended frequency and dynamic ranges.
The issue was not so much to do with pitch and loudness but with the intensity and the consistent presence of new sonic textures such as machine noise: distorted high frequency textures, mid-range drones and sub-sonic hums. Stop now and listen: what is the sound that you can identify as being physically furthest away from you at present? Traffic - jet engine - heating - computer fan - air conditioning - an animal - the weather - the TV? What is the sound closest to you that you can identify? Can you hear your heart beat - your blood flow?

To accommodate these developments in technology (our ears have been in a continual state of adapting: we screen sounds - consciously or subconsciously), we use a range of methods for focusing or using different modes of listening: blocking or focusing on the voice within a soundscape, selectively hearing a voice within a group of voices, identifying a person by their voice, concentrated focused listening, deep listening, listening to hear within a sound, or beyond the surface of a sound, listening for the concealed, listening for character, or for the emotive implications of a vocal sound. Often this process involves a multi-modal experience, such as hearing and seeing. Together these senses operate in tandem as a means of confirming the signal one first perceives.
We hear the voice and look into the face of the speaker for confirmation of intent. The voice sounds happy, the face is smiling, and so we confirm that the person speaking is happy. The voice sounds happy but the body language and face are neutral - is this person being ironic? Manipulative? Or not interested?
During our evolution we have developed an interpretative ear with the capacity to understand what we hear as vocal sound and what we understand as being the emotive intent associated with that voice - intuitively or through analytical reasoning. The sophistication of this developed hearing goes to an understanding of the complexity contained within the mixed modal communicative experience.
The mixed mode communicative experience has become a dominant interpretative paradigm - an audiovisual model. Film, video and screen-based media have been prominent in shaping the communicative language where the voice is used as a part of a total emotive experience. This has had a formative effect on listening - the way we hear or listen to a voice and the way we listen to, or block out, a voice or voices.
Has this resulted in our being less able to hear and understand without seeing the owner of the voice? Has our ability to listen been constrained by a world that is more visually aware? After all, our ears are always open whereas our eyes are continually being directed to what we want to look at. Are we not more likely to refocus our listening while still hearing, than to shut our eyes and not see at all?

So where is the voice now? We live in a time when both speaker and listener are confused about the multiplicity of meaning within an emotive vocal expression. Entangled in complexities - the process of emotive signalling and reception has been reformatted - our intuitions and our ability to cope has turned us into selective listeners who often also choose to limit the extent of our emotive expressiveness. We are able to selectively listen to what we want to hear - listening for what is familiar or easy, manipulating our emotive language so as not to say too much about how we actually feel, tempering our emotive utterances to fit within the context or space where we find ourselves being expressive.
No screaming on the bus please - and no whispering to a crowd if you want to motivate them. No shouting at anyone if you are in a small space. If you need to shout at someone make sure you are across the road from them and that the road that divides you is busy with traffic. Then shout as loudly as you like because no one will hear it as shouting - few will hear it at all against the noisy ambience.
Breathe deep - suck as much fresh air into your lungs as possible - and listen to the gasps of the ingressive and hear the sadness and the breathlessness of our time: emotions constrained in voicing the sounds of sighs.
Images by Dr John Rubin and the author.
Further links
Frank Millward - AMC
profile
Frank Millward - homepage
© Australian Music Centre (2010) — Permission must be obtained from the AMC if you wish to reproduce this article either online or in print.
Frank Millward is a composer currently producing work in the area of Live Art - his research explores cross-disciplinary relationships between technology, science and art where focus is given to the innovative use of sound and moving image in order to produce new forms of performance. He lectures in digital media, audio art and performance in the School of Fine Art at Kingston University, London.
Comments
Be the first to share add your thoughts and opinions in response to this article.
You must login to post a comment.